| PsychosisBank | 
| IRB Approval |
1. IRB Principles
PsychosisBank members who are interested in contributing their data need to make sure that they obtain IRB approval for their study, along with informed consent from individual participants. There are no standard forms for IRB applications, since every university or institute creates their own forms, procedures, and templates. However, if prospective contributors wish to access previously submitted templates, please write to discourseinpsychosis@gmail.com. For the purposes of contributing to PsychosisBank, the important thing is to select the appropriate level of access to the data that participants are being asked to grant. To help you determine this, you can refer to the OPTIONS summary for the 9 options that are available, of which only four are available for PsychosisBank contributions. We would recommend that you ask participants to permit unrestricted access with pseudonymization of the transcripts (Options 1 and 2). You should include on your form the fact that participants always have the right to request that parts or all of the data in which they participate be removed from PsychosisBank at any time.2. Contributions of Archival Data
Often researchers will wish to contribute data collected in projects thairbt have already been completed. In such cases, it may be difficult or impossible to contact participants to obtain a new consent form. However, IRBs are allowed to permit including these data in TalkBank, if certain conditions are met.- The original consent forms should not have exclusionary language such as "These data will only be made available to Professor XYZ and her laboratory". If the consent forms says something like "These data will only be made available to qualified researchers," then inclusion in TalkBank should be allowed, as long as only qualified researchers are given the necessary password. If the consent form is still more general, then passwords may not be necessary.
- Data should be anonymized.
- Additional protection is possible, as described on the options summary page .
- It is important to emphasize that granting agencies stipulate that data collected with federal funds should be made available to researchers, as long as anonymity is preserved.
3. GDPR Compliance
The General Data Protection Regulation (GDPR) establishes rules for personal data on the web. The EU web site for GDPR issues is https://gdpr-info.eu/. For TalkBank, there are five core GDPR issues- Commercial purposes issue: GDPR is designed to apply to data transferred for commercial purposes. TalkBank has no commercial purposes. However, it could still apply if TalkBank were to collect emails and addresses, which it does not do.
- The scientific data issue: A good summary of these issues can be found in this Nature article which notes that, consent is given "to certain areas of scientific research when in keeping with recognised ethical standards for scientific research." Article 89 of the GDPR states that, "Where personal data are processed for scientific or historical research purposes or statistical purposes, Union or Member State law may provide for derogations from the rights referred to in Articles 15, 16, 18 and 21 subject to the conditions and safeguards referred to in paragraph 1 of this Article in so far as such rights are likely to render impossible or seriously impair the achievement of the specific purposes, and such derogations are necessary for the fulfilment of those purposes." In other words, data-sharing is allowed for research purposes. In addition, Recital 113 allows for transfers of data from a limited number of data subjects for scientific purposes for an increase of knowledge.
- The informed consent Issue: NIH IRB informed consent guidelines are in accord with the GDPR Consent rules. Given this, if participants give consent for making data available to qualified researchers, then this should be approved. GDPR emphasizes also that this consent must be revocable and that there should be methods for allowing participants to revoke consent.
- The Code of Conduct issue: Article 40 allows for development of a Code of Conduct to facilitate data transfer to non-EU countries.
4. Deidentification
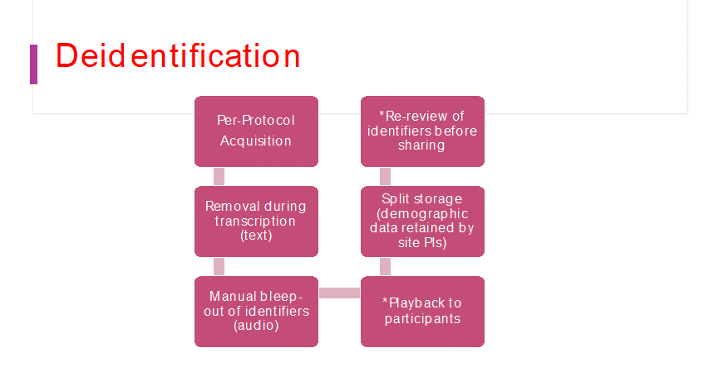
Several filters (as shown below in Figure 1) Are used to de identify recorded speech data before storage in the databank. Firstly, the DISCOURSE protocol explicitly avoids using proper nouns and names/addresses. Second, the transcribed data is checked, and any proper names are replaced by common names (e.g., ‘McGill’ will be changed to ‘University’) or bleeped out (for audio data). If requested, we will play back the recorded responses to check if the participant is comfortable with the degree of anonymity. Identifying demographics will not be stored alongside the speech data to reduce triangulation. Finally, sharing is controlled by password protection, and a re-review is done to remove identifying information before sharing is initiated. e.g., In order to de-identify transcripts, it is important to replace any last names with the word "Lastname" with a capital L. Also addresses or local city names should be replaced with "Addressname" with a capital A. Other forms include "Cityname", "Schoolname", "Hospitalname" and so on. These same English words should be used even in other languages. It is not crucial to replace first names unless they are very unique.
The EU Amnesia project at https://amnesia.openaire.eu provides software for deidentification of spreadsheet data.
The Canadian CONP Ethics and Governance Committee has a series of recommendations for deidentification of neuroimaging data .
For audio deidentfication, we can then use the occurrences of the terms Lastname and Address in the transcripts to guide the removal of the names and addresses from the corresponding segment in the audio track. You can follow the suggestions in the section of the CLAN manual on "Audio Anonymization". Once this is done, children and others can only be identified by people who already know them. Because of this, contribution of audio is equivalent in IRB terms to contribution of transcripts.
You can also save yourself a lot of trouble if you avoid using idetifying information when making recordings.
5. Voiceprints
Researchers often ask about whether they need to request additional IRB approval for contributing audio data. The concern is that audio data may be less confidential than transcript data. However, as long as identifying material is removed from both transcripts and audio, they do not present additional confidentiality issues.
Some reviewers and IRB committees believe that spoken data is identifiable through voice recognition technology. However, this judgment is based on a confusion between closed-set identification and open-set identification. Closed-set identification relies on a pre-existing pool of voiceprints from a given group, such as members of a company or subscribers to a service. Open-set identification does not rely on this pre-existing pool of voiceprints. As noted by Togneri and Pullella (2011), "in open-set identification the unknown individual can come from the general population. However as identification is always carried out against a finite, known pool of individuals it is not possible to identify arbitrary people."
Togneri, R., & Pullella, D. (2011). An overview of speaker identification: Accuracy and robustness issues. IEEE circuits and systems magazine, 11(2), 23-61. pdf
As Yuan and Liberman (2008) discovered, speaker identification in even a closed group of Supreme Court judges in TalkBank's SCOTUS corpus is still very difficult.
Yuan, J., & Liberman, M. (2008). Speaker identification on the SCOTUS corpus. Journal of the Acoustical Society of America, 123(5), 3878. pdf 5. Contributions to PsychosisBank Research with subjects with mental health conditions requires additional access restriction, such as password protection. It may also require more complete IRB documentation. In this regard, researchers will find these additional IRB-approved materials useful:
- A generic informed consent form in the CMU format .
- Consent form fromCMU Should you have any further questions specific to PsychosisBank, please contact with discourseinpsychosis@gmail.com, Brian MacWhinney (macw@cmu.edu) or Lena Palaniyappan (lena.palaniyappan@mcgill.ca)